
import کردن دادهها در ابزار Disco بسیار آسان است. این ابزار به طور خودکار زمان و دیگر ستونها را تشخیص داده و تنظیمات و بارگزاری مجموعه داده ها را با سرعتی بسیار زیاد انجام دهد.
در این فصل جزئیات بیشتری در مورد نوع فایل هایی که می توانید در Disco بارگیری کنید و نحوه کار import داده را یاد میگیرید.
import مجموعه داده ها
import با نماد پوشه در شکل 1 نشان داده می شود.
![]()
شکل 1: نماد Open در Disco
کلیک کردن روی نماد پوشه انتخاب پرونده را باز می کند و به شما امکان می دهد یک مجموعه داده را در فضای کاری خود وارد کنید. شما نماد Open را در گوشه سمت چپ بالای پنجره Disco خواهید یافت همانطور که در شکل 2 نشان داده شده است.
![]() شکل 2: فشار دادن نماد Open باعث باز شدن پنجره انتخاب پرونده می شود. (در Windows شما پنجره استاندارد انتخاب پرونده ویندوز را خواهید دید.)
شکل 2: فشار دادن نماد Open باعث باز شدن پنجره انتخاب پرونده می شود. (در Windows شما پنجره استاندارد انتخاب پرونده ویندوز را خواهید دید.)
بیشتر اوقات شما فایل ها را با پسوندهای زیر باز و پیکربندی می کنید:
- .csv (فاصله جدا شده با کاما) ، یا پرونده های .zip حاوی یک پرونده CSV
- .txt (فایل های متنی) ، یا پرونده های .zip حاوی یک فایل TXT
- .xls و .xlsx (مایکروسافت اکسل)
اگر یک فایل Excel را باز کنید که دارای چندین شیت دارای داده (پر) باشد ، Disco به شما اجازه می دهد که انتخاب کنید که کدام یک را می خواهید وارد کنید به شکل 3 توجه کنید.
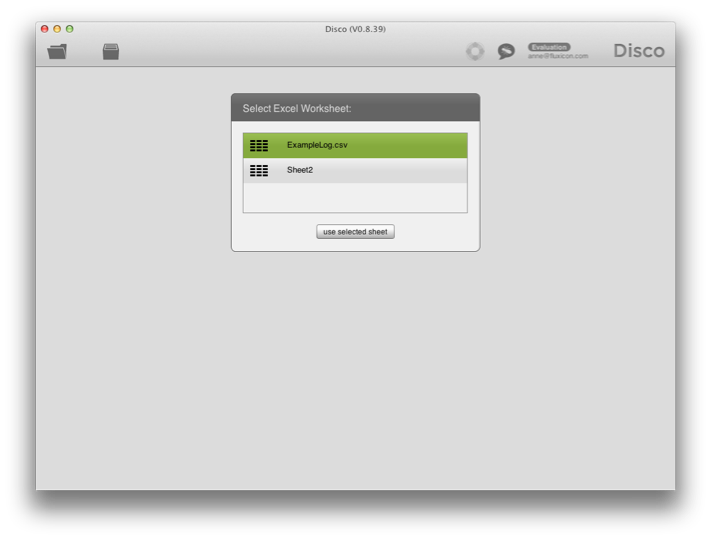 شکل 3: اگر چندین برگ غیر خالی در فایل Excel خود دارید، Disco به شما اجازه می دهد انتخاب کنید که کدام یک را می خواهید وارد کنید.
شکل 3: اگر چندین برگ غیر خالی در فایل Excel خود دارید، Disco به شما اجازه می دهد انتخاب کنید که کدام یک را می خواهید وارد کنید.
علاوه بر این، Disco پرونده های پیش پیکربندی شده را در انواع قالب های استاندارد می خواند:
- .mxml و .mxml.gz (برای اطلاعات بیشتر در مورد پرونده های مربوط به MXML، مراجعه کنید به MXML و XES)
- .xes و .xes.gz (برای اطلاعات بیشتر در مورد پرونده های مربوط به XES، به MXML و XES مراجعه کنید)
- .fxl (برای اطلاعات بیشتر در مورد پرونده های log Disco، به Disco Log Files مراجعه کنید)
- .dsc (برای اطلاعات بیشتر در مورد پروژه های Disco، به Disco Projects مراجعه کنید)
فرمت مورد نیاز برای پرونده های CSV، Excel و TXT
می توانید پرونده هایی را در قالب نشان داده شده در شکل 4 باز کنید. انتظار می رود هر خط یا ردیف حاوی اطلاعات مربوط به یک رویداد یا فعالیت اجرا شده در فرآیند شما باشد. شما حداقل به یک ستون ID پرونده، یک فعالیت و به طور ایده آل یک یا چند ستون مربوط به زمان نیاز دارید.
اگر نمی دانید case ID یا یک فعالیت چیست، لطفاً مقدمه ای درباره گزارش رویداد در بخش گزارش رویداد را بخوانید.
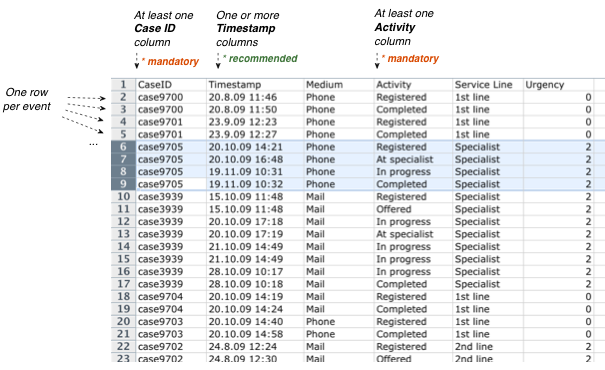
شکل 4: مثال پرونده Excel: شما باید برای هر فعالیتی که در فرآیند انجام شده است، یک ردیف داشته باشید، همراه با یک ID پرونده، یک فعالیت و یک شناسه زمان.
توجه داشته باشید که سطرهای پرونده شما نیازی به مرتب سازی ندارند. Disco فعالیت ها را بر اساس زمان در پرونده شما مرتب می کند. فقط اگر از یک پرونده ای استفاده کنید که ستون زمان ندارد (یا اگر برخی از رویدادهای در همان پرونده دارای زمانهای یکسان باشند)، رویداد ها با ترتیبی که در پرونده ظاهر می شوند وارد می شوند.
ترتیب و نام ستون ها نیز مهم نیست. به عنوان مثال، لازم نیست که ستون شناسه پرونده شما “CaseID” مانند شکل 4 نامگذاری شود. مهم این است که شما حداقل یک ستون داشته باشید که بتوان از آن به عنوان شناسه پرونده استفاده کرد و حداقل یک ستون که بتوان از آن به عنوان نام فعالیت استفاده کرد. می توانید در مرحله پیکربندی به Disco بگویید که کدام ستون چه معنی میدهد.
ستون زمان نیازی به فرمت خاصی ندارد. به جای آن، Disco شناسه های زمانی (Timestamp) را در فرمتی که شما ارائه می دهید می خواند اگر چندین ستون شناسه زمان دارید که نشان می دهد فعالیت در چه زمانی برنامه ریزی شده، شروع شده و تکمیل شده است، می توانید از آن استفاده کنید.
سرانجام، شما می توانید به تعداد دلخواه ستون های داده اضافی داشته باشید. آنها به عنوان ویژگی ها گنجانده می شوند که می توان از آنها در تجزیه و تحلیل خود بعداً استفاده کرد.
اگر داده های شما در Excel نیستند بلکه در پایگاه داده یا سیستم اطلاعاتی دیگری هستند، بهترین فرمت برای استخراج داده ها به عنوان فایل جدا شده با کاما (CSV) است. منطقا، یک فایل CSV بسیار شبیه به جدول Excel شکل 4 است: هر خط حاوی یک رویداد است و سلول های مختلف ستون با یک کاما (یا سایر کاراکتر جدا کننده) جدا می شوند. با این حال، یک فایل CSV محدودیت 1 میلیون خطی که Excel دارد را ندارد و بنابراین برای حاوی مجموعه داده های بسیار بزرگتر نیز مناسب است. شما می توانید یک فایل CSV را در یک ویرایشگر متن استاندارد باز کنید.
در اینجا نمونه ای از اقتباس از یک گزارش رویداد در فرمت CSV آورده شده است:
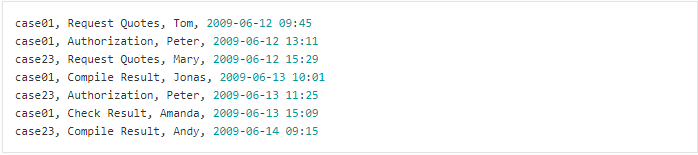
خط اول یک رویداد را توصیف می کند: که در هنگام اجرای پرونده “case01” رخ داده است که توسط اجرای فعالیت “Request Quotes” رخ داده است جایی که این فعالیت توسط منبع “Tom” اجرا شده بود و در آن فعالیت در 12 ژوئن 2009، در ساعت 9:15 صبح اجرا شده بود.
کاراکتر جدا کننده می تواند یک کاما (“،”) ، نقطه ویرگول (“؛”) ، تب (“t”) یا کاراکتر (“|”) باشد. اگر کاراکتر جداکننده در محتویات پرونده شما موجود باشد، عناصر محتوا باید توسط نقل قول ها گروه بندی شوند. به عنوان مثال، اگر از کاما به عنوان کاراکتر جداکننده استفاده می کنید و نام فعالیت شما Request Quotes، Standard است (بنابراین، نام فعالیت خود نیز دارای یک کاما است):

پس نام فعالیت باید توسط نقل قول ها جدا شود:

همه این موارد کاملاً استاندارد هستند و توسط اکثر پایگاه داده ها یا نحوه اکسورت کردن دادهها به طور خودکار انجام می شوند.
پیکربندی تنظیمات import
هنگامی که فایل Excel، CSV یا متن خود را در Disco باز کردید، یک صفحه پیکربندی ورود مانند شکل 5 مشاهده می کنید.
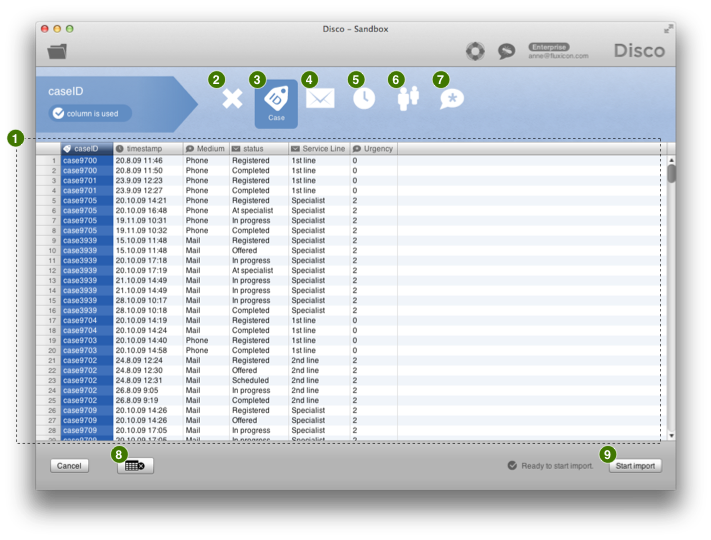 شکل 5: صفحه پیکربندی ورودی در Disco.
شکل 5: صفحه پیکربندی ورودی در Disco.
در صفحه ورود، همان ستون هایی را می بینید که اگر فایل را در Excel باز کرده بودید داشتید (برای مقایسه به شکل 4 مراجعه کنید). Disco شروع به حدس زدن اینکه هر ستون ممکن است به چه معنی باشد (سعی در شناسایی شناسه پرونده، فعالیت و شناسه زمان) می کند، اما می توانید قبل از ادامه ورود دادهها، پیکربندی را بررسی و اصلاح کنید.
گزینه های پیکربندی زیر برای هر ستون در دسترس است:
- حذف: ستون انتخاب شده را نادیده می گیرد (اصلاً وارد نخواهد شد).
- Case: ستون انتخاب شده را به عنوان شناسه پرونده تنظیم کنید
- Activity: ستون انتخاب شده را به عنوان نام فعالیت پیکربندی می کند.
- Timestamp: نشان می دهد که ستون انتخاب شده حاوی شناسه زمان است.
- Resource: ستون را به عنوان ستون منبع برای تجزیه و تحلیل سازمانی پیکربندی می کند.
- Others: ستون انتخاب شده را به عنوان ویژگی اضافی شامل می کند.
پیکربندی فعلی برای هر ستون توسط نماد پیکربندی کوچک در هدر هر ستون در جدول داده نشان داده می شود.
-
Exclude/Include. با این دکمه می توانید همه ستون ها را به طور همزمان مستثنی یا شامل کنید. این زمانی مفید است که ستون های مختلفی دارید و فقط می خواهید چند مورد از آنها را درنظر بگیرید یا حذف کنید.
-
Start Import. پس از پیکربندی ستون ها، می توانید با فشار دادن این دکمه شروع به وارد کردن دادهها کنید.
شرایط حداقلی ورود داده
قبل از شروع وارد کردن فایل خود، باید حداقل یک ستون شناسه پرونده و یک ستون فعالیت را پیکربندی کنید.
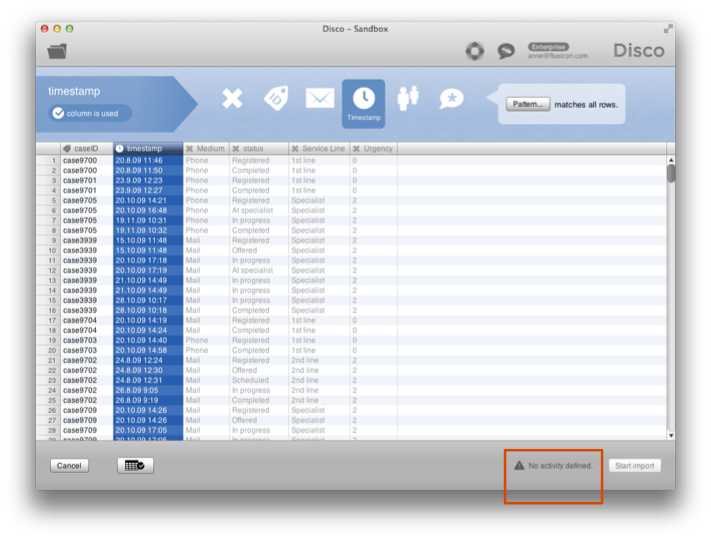 شکل 6: Disco به شما اعلام می کند اگر هنوز ستون فعالیت یا شناسه پرونده پیکربندی نشده است.
شکل 6: Disco به شما اعلام می کند اگر هنوز ستون فعالیت یا شناسه پرونده پیکربندی نشده است.
اگر این الزامات حداقلی برآورده نشوند، Disco به شما می گوید که مشکل مرحله پیکربندی کدام است: برای مثال، در شکل 6 شما یک پیکربندی را مشاهده می کنید که هنوز ستون فعالیت تعریف نشده است و بنابراین دکمه Start import هنوز غیرفعال است. در شکل 7، ستون وضعیت برای نام فعالیت استفاده می شود و دادهها آماده ورود است.
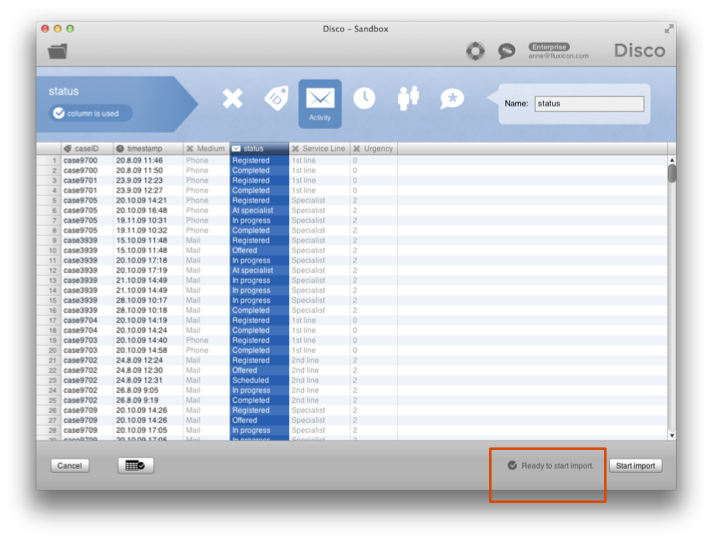 شکل 7: به محض اینکه همه ستون های مورد نیاز پیکربندی شوند، وارود دادهها می تواند شروع شود.
شکل 7: به محض اینکه همه ستون های مورد نیاز پیکربندی شوند، وارود دادهها می تواند شروع شود.
ا
پیشرفت import
به محض اینکه دکمه Start import را فشار دادید، Disco شروع به خواندن فایل کامل طبق تنظیمات داده شده می کند. پیشرفت ورود همراه با نشانگر میزان داده خوانده شده نمایش داده می شود؛ (1) را در شکل 8 ببینید.
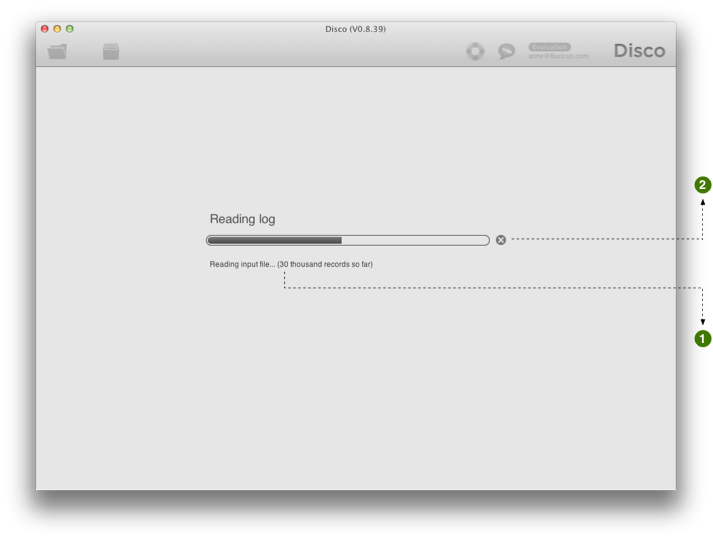 شکل 8: پس از پیکربندی ستون های خود، ورود می تواند شروع شود. پیشرفت را خواهید دید (1) و می توانید اگر لازم بود ورود دادهها را متوقف کنید (2).
شکل 8: پس از پیکربندی ستون های خود، ورود می تواند شروع شود. پیشرفت را خواهید دید (1) و می توانید اگر لازم بود ورود دادهها را متوقف کنید (2).
اگر می خواهید فرایند ورود دادهها را متوقف کنید، می توانید با فشار دادن x در سمت راست نوار پیشرفت این کار را انجام دهید؛ (2) در شکل 8 را ببینید.
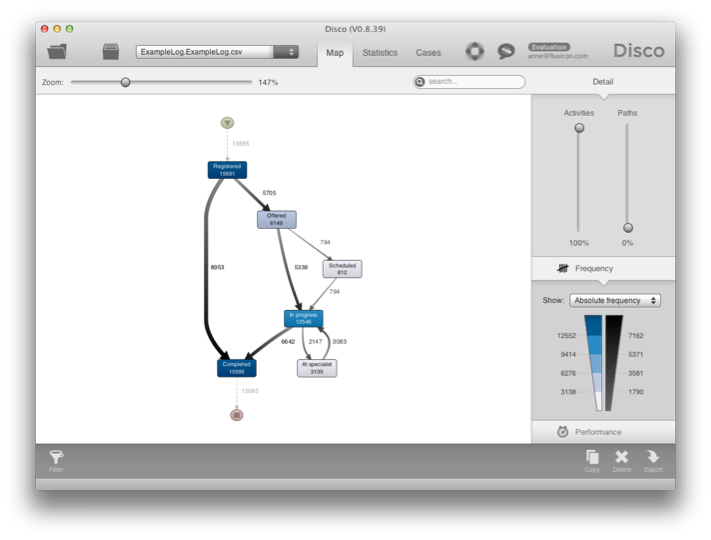 شکل 9: به محض اینکه ورود دادهها تمام شد، مستقیماً به نمای نقشه منتقل می شوید.
شکل 9: به محض اینکه ورود دادهها تمام شد، مستقیماً به نمای نقشه منتقل می شوید.
پس از ورود دادهها، مستقیماً به نمای نقشه منتقل می شوید، جایی که می توانید جریان فرآیند را بررسی کنید و تجزیه و تحلیل خود را شروع کنید.
ذخیره تنظیمات import
تنظیمات ورود دادهها به طور خودکار ذخیره می شود و دفعه بعدی که همان فایل یا فایل مشابه را بارگیری می کنید، بازیابی می شود.
پیکربندی الگوهای شناسه زمان
شناسه های زمان می توانند در فرمت های مختلف باشند. به عنوان مثال، تاریخ 4 آگوست 2012 ممکن است به عنوان 04/08/12 یا 08/04/12، به عنوان 2012-08-04، یا به عنوان 4.8.2012 نمایش داده شود، و یا به روش های دیگر. همین امر برای زمان روز نیز صادق است. قراردادهای مختلف در مورد ترتیب، کاراکترهای جداکننده، با یا بدون فضای خالی و غیره اغلب باعث دردسر برای تجزیه و تحلیل داده ها در زمینه شناسه های زمان می شود.
وقتی اولین ردیف های مجموعه داده خود را به تجزیه و تحلیل می کند تا پیشنهاداتی برای چگونگی پیکربندی ستون های داده خود ارائه دهد (مشاهده پیکربندی تنظیمات واردات)، الگوهای شناسه زمانی مختلف با داده های شما آزمایش می شوند تا ببینند کدام یک بهترین تطابق را دارد. این بدان معناست که در بیش از 90٪ موارد قالب شناسه زمان شما به صورت خودکار تشخیص داده می شود و شما نیازی به پیکربندی دستی در مورد آن ندارید.

شکل 10: بازخورد در مورد میزان مطابقت تعداد سطرهای ستون زمان انتخاب شده با الگوی زمان فعلی.
برای بررسی و تغییر الگوی شناسه زمان، دکمه Pattern… را فشار دهید (1) را در شکل 10 ببینید). این صفحه پیکربندی الگوی شناسه زمان را که در شکل 11 نشان داده شده است، باز می کند.
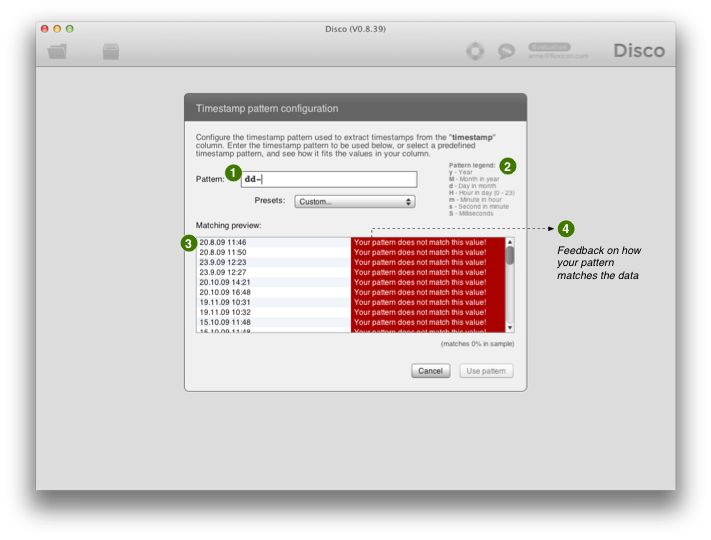 شکل 11: اگر الگوی فعلی (1) با داده های شما (3) مطابقت ندارد، پیش نمایش تعاملی به شما بازخورد مستقیم (4) خواهد داد.
شکل 11: اگر الگوی فعلی (1) با داده های شما (3) مطابقت ندارد، پیش نمایش تعاملی به شما بازخورد مستقیم (4) خواهد داد.
صفحه پیکربندی الگوی شناسه زمان به شما امکان می دهد تا الگوی شناسه زمان را برای مطابقت با داده های خود بررسی و اصلاح کنید.
Disco به شما اجازه می دهد تا مستقیماً الگوی تاریخ و زمان را در فرمت داده ساده جاوا [SimpleDateFormat] مشخص کنید. شما می توانید برای نمونه الگوها را در تنظیمات پیش فرض جستجو کنید، اما Disco به طور خودکار آنها را امتحان می کند. بنابراین، اگر الگوی شناسه زمان شما به طور خودکار مطابقت ندارد، بهترین کار این است که الگوی سفارشی خود را مشخص کنید. برای مشخص کردن یک الگوی سفارشی، می توانید این مراحل را دنبال کنید:
1.به اولین جفت نمونه تاریخ از فایل خود در پیش نمایش نگاه کنید؛ (3) را در شکل 11 ببینید. بفهمید که چگونه الگو شروع می شود: آیا آن سال است؟ ماه؟ به عنوان مثال، در شکل 11 روز ماه است.
2. وبررسی کنید که کدام حرف نماینده نهاد تاریخ یا زمان شما است. به عنوان مثال، روز ماه با حرف کوچک “d” نمایش داده می شود.
شما می توانید یک لیست کامل از الگوها (از جمله نمونه های الگو برای زمان های مختلف، با AM/PM و غیره) را در [SimpleDateFormat] پیدا کنید.
3.الگوی سفارشی خود را در قسمت ورود الگو تایپ کنید؛ (1) در شکل 11 ببینید. حرف نماینده نهاد تاریخ یا زمان خود را به همان تعداد دفعاتی که نهاد مربوطه در قالب دارد، تایپ کنید. به عنوان مثال، تاریخ روز ماه با حداکثر دو رقم نشان داده می شود. بنابراین، شما شروع به تایپ dd برای مطابقت با روز در ابتدای الگو شناسه زمان خود می کنید.
4.به نمونه های شناسه زمان در پیش نمایش خود (3) دوباره نگاه کنید و پیدا کنید که چگونه الگو بخش های مختلف زمان و تاریخ را جدا می کند. آیا یک نقطه (.) یا یک خط تیره (-) یا فقط یک فضای سفید است؟ به عنوان مثال، در شکل 11 روز ماه و ماه با یک نقطه جدا می شوند. بنابراین، شما الگوی خود را از dd به dd.MM برای مطابقت با هر دو روز و ماه گسترش می دهید.
5.در هر مرحله بررسی کنید که الگوی ارائه شده تا کنون نتیجه مورد انتظار را می دهد. پنجره پیش نمایش به شما بازخورد تعاملی در حالی که شما در حال تایپ الگو خود هستید؛ (3) را در شکل 11 ببینید. به عنوان مثال، در شکل 11 الگوی dd- غلط است و با شناسه های زمانی در نمونه داده مطابقت ندارد.
6.ادامه دهید تا زمانی که همه عناصر تاریخ و زمان به طور کامل مطابقت داشته باشند. به عنوان مثال، الگوی dd.MM.yy HH:mm با همه شناسه های زمانی در شکل 12 مطابقت دارد.
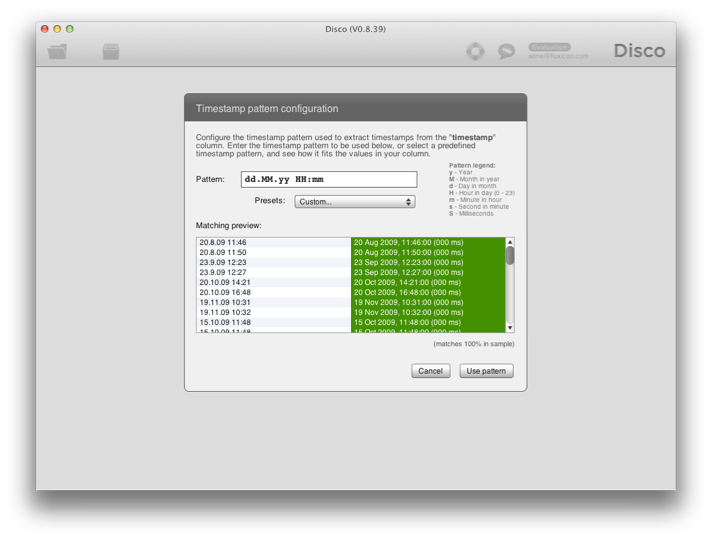 شکل 12: هنگامی که شما یک الگوی مطابق پیدا کرده اید می توانید از آن استفاده کنید.
شکل 12: هنگامی که شما یک الگوی مطابق پیدا کرده اید می توانید از آن استفاده کنید.
هنگامی که شما تمام عناصر تاریخ و زمان را برای نمونه شناسه های زمانی در پیش نمایش خود مطابقت داده اید، می توانید بر روی Use pattern کلیک کنید و Disco الگوی سفارشی شما را برای آینده به خاطر خواهد سپرد.
ترکیب چندین ستون شناسه پرونده، فعالیت یا منبع
در بیشتر موارد، یک کاندیدای واضح برای ستون شناسه پرونده و ستون فعالیت وجود دارد. اما اغلب چندین دیدگاه وجود دارد که می توان بر روی داده ها انجام داد.
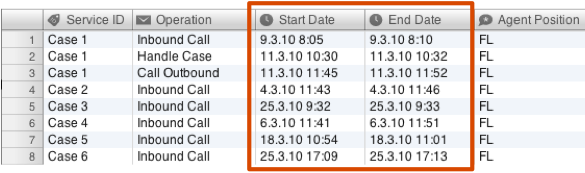
در Data Requirements ما مدل ذهنی را که در پشت فرایند استخراج و چگونگی تعیین سطح جزئیات برای مراحل فرایند توضیح دادیم. اگر به Combined Activity مراجعه کنید، می توانید ببینید که چگونه یک نقشه فرایند دقیق تر برای مثال مرکز تماس می تواند با استفاده از هر دو ستون Operation و Agent Position به عنوان نام فعالیت کشف شود.
برای اینکه کار شما را راحت تر کند، Disco اجازه می دهد تا چندین ستون را برای موارد زیر ترکیب کنید:
- شناسه پرونده
- فعالیت
- فیلد منبع
این کار با اختصاص چند ستون به عنوان شناسه پرونده، فعالیت یا منبع شما انجام می شود. محتویات این ستون ها بهم متصل (متصل) می شوند.
برای مثال، در شکل 5 فقط ستون Status به عنوان فعالیت تنظیم شده بود. ستون Service Line به عنوان یک ویژگی ساده گنجانده شد. این منجر به نقشه فرایند نشان داده شده در شکل 9، با نام های فعالیت مانند Offered، Scheduled، و In progress شد.
در غیر این صورت، شما می توانید هم Status و Service Line را به عنوان فعالیت مانند شکل 13 تنظیم کنید. این سپس به شما یک نقشه فرایند دقیق تر می دهد که در شکل 14 با نام فعالیت مانند Offered-2nd line، Offered-Specialist، و In progress-Specialist مشاهده می کنید.
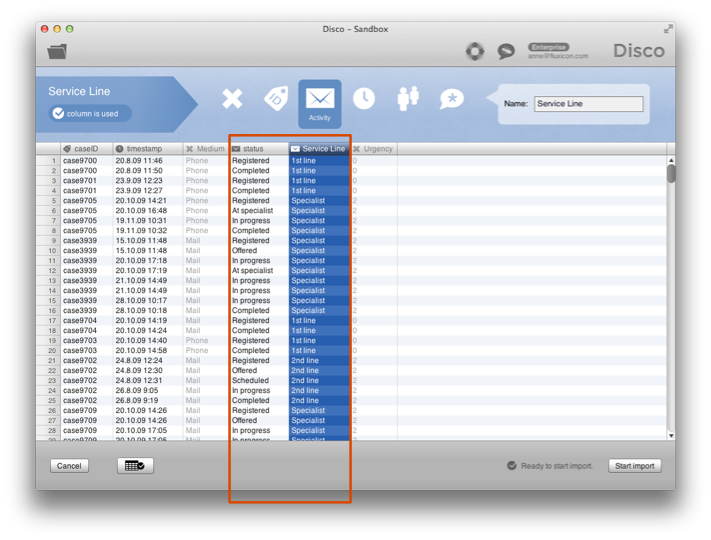 شکل 13: با گنجاندن خط خدمات (1st line، 2nd line، یا Specialist) در نام فعالیت …
شکل 13: با گنجاندن خط خدمات (1st line، 2nd line، یا Specialist) در نام فعالیت …
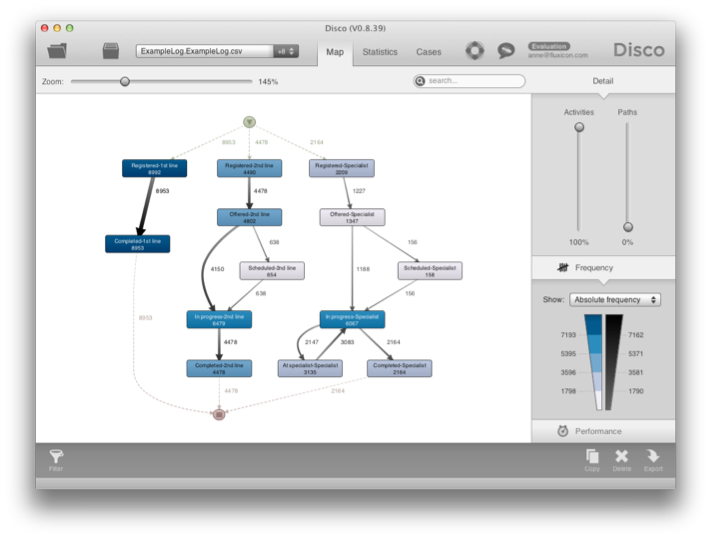 شکل 14:می توان فعالیت هایی را که برای موارد حل شده در این بخش های مختلف سازمان انجام شده است، تشخیص داد.
شکل 14:می توان فعالیت هایی را که برای موارد حل شده در این بخش های مختلف سازمان انجام شده است، تشخیص داد.
در مثال شکل 13 Service Line یک ویژگی ایستا است – برای هر پرونده بسته به اینکه در کجا در نهایت حل شد، اختصاص داده شده است (بنابراین، شما انتقال واقعی یک پرونده را نمی بینید که توسط 1st line گرفته شده و به 2nd line تحویل داده شده است). این به دلیل نحوه ثبت داده ها است (به مثال مرکز تماس در Combined Activity مراجعه کنید، جایی که انتقال های خط خدمات به صورت دقیق تری ثبت می شوند).
در نتیجه، شما می توانید جریان های فرایند مختلف برای 1st line، 2nd line، و Specialist process categories را در یک نمای کنار هم مشاهده کنید. شما می توانید همین کار را برای محصولات مختلف، دپارتمان ها یا سایر دسته بندی های جالب برای فرآیند خود انجام دهید. نتیجه مشابهی را می توان با استفاده از Attribute Filter برای فیلتر کردن صریح نسخه های مختلف فرآیند بر اساس ویژگی Service Line (یا سایر دسته بندی ها) حاصل کرد.
جابجایی موارد، فعالیت ها و منابع
شبیه به ترکیب چندین ستون فعالیت (مشاهده کنید Combining Multiple Case ID, Activity, or Resource Columns)، نمای های مختلفی از فرآیند می توان با تغییر پیکربندی ستون گرفته شود.
برای مثال، در شکل 15 ستون Resource از نمونه ورودی خرید پیکربندی شده است فعالیت . نتیجه یک نقشه فرایند است که در آن می توانید ببینید که چگونه کار بین افراد منتقل می شود همانطور که در شکل 16 نشان داده شده است.
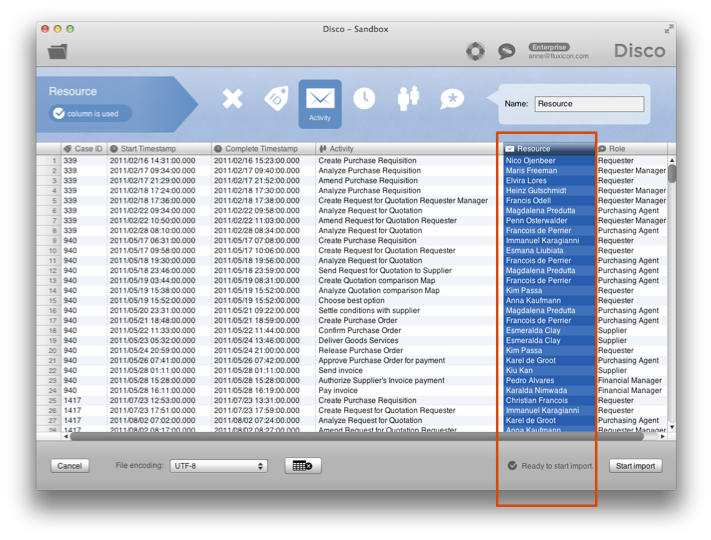 شکل 15: پیکربندی ستون منبع به عنوان فعالیت
شکل 15: پیکربندی ستون منبع به عنوان فعالیت
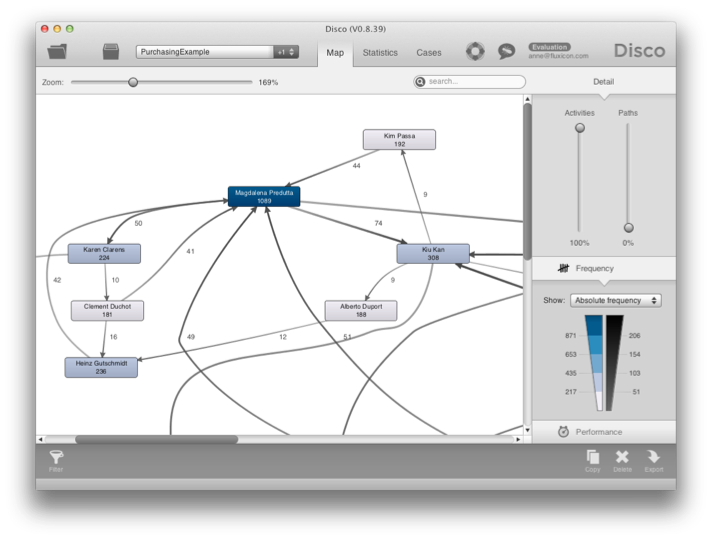 شکل 16:می توانید ببینید که چگونه فرآیند بین افراد جریان دارد.
شکل 16:می توانید ببینید که چگونه فرآیند بین افراد جریان دارد.
به همین ترتیب، در شکل 17 یک نمای مبتنی بر نقش افراد در سازمان در فرآیند نمایش داده شده است. با پیکربندی ستون Role – ستونی که در سمت راست ستون منبع در شکل 15 قرار دارد – به عنوان فعالیت، می توان دید که فرآیند چگونه بین نقش های مختلف در سازمان جریان دارد.
نمایش عملکرد در شکل 18 نشان می دهد که مدیر یک انسداد است با گرفتن حدود هفت روز به طور متوسط قبل از ارسال پرونده به عامل خرید.
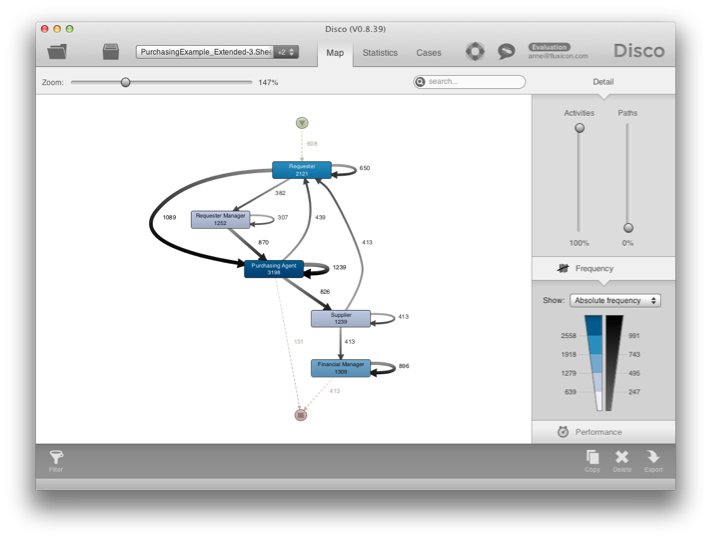 شکل 17: با پیکربندی ستون نقش به عنوان فعالیت، جریان فرآیند بین عملکردها به تصویر کشیده می شود.
شکل 17: با پیکربندی ستون نقش به عنوان فعالیت، جریان فرآیند بین عملکردها به تصویر کشیده می شود.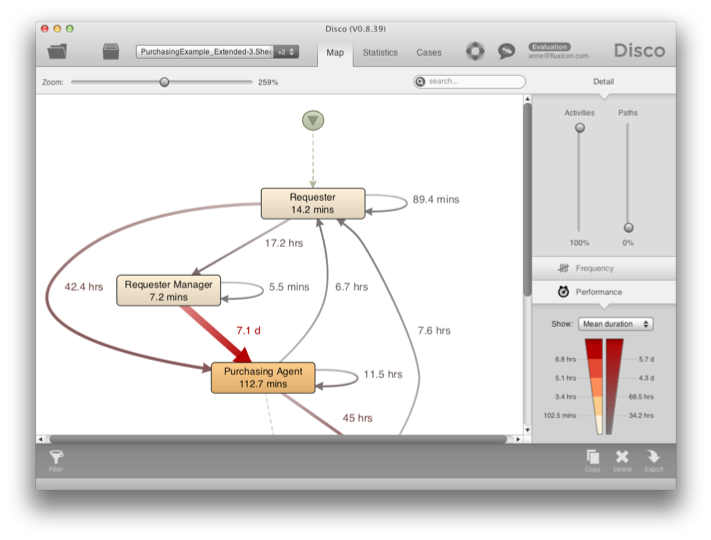 شکل 18: به دلیل کمبود موجودی، عامل خرید باعث بیشترین تأخیر در فرآیند خرید می شود.
شکل 18: به دلیل کمبود موجودی، عامل خرید باعث بیشترین تأخیر در فرآیند خرید می شود.
برای ارائه مثال تعویض شناسه پرونده، تصور کنید فرآیند مراقبت های بهداشتی را در نظر داریم که در آن معمولاً می خواهید فرآیند تشخیص و درمان را از دیدگاه بیمار مشاهده کنید. بنابراین، ستون شناسه بیمار گزینه طبیعی برای شناسایی پرونده خواهد بود. با این حال، همچنین می تواند جالب باشد که مقایسه کنید که چگونه پزشکان مختلف کار می کنند تا بهترین شیوه ها را شناسایی و ترویج کنند. در این حالت، نام پزشک (که معمولاً به عنوان ستون منبع پیکربندی می شود) بخشی از شناسه پرونده خواهد بود.
بسته به اینکه شما داده های خود را چگونه می بینید، می توان چندین نمای فرآیند را در نظر گرفت (همچنین به Data Requirements مراجعه کنید). با آسان سازی تفسیر ستون ها به روش های مختلف، همانطور که در اینجا نشان داده شده است، با ترکیب چندین ستون (ترکیب چند شناسه پرونده، فعالیت یا ستون منبع)، و با اجازه دادن به شما برای عقب رفتن و تنظیم پیکربندی (تنظیم پیکربندی واردات)، Disco تشویق می کند که فرآیند خود را به صورت چند وجهی کاوش کنید.
شامل چندین ستون شناسه زمان
معمولاً حداقل یک شناسه زمان برای مرتب کردن صحیح وقایع مربوط به هر پرونده مورد نیاز است، و در بسیاری از موارد یک شناسه زمان همه چیز شماست (مانند مثال در شکل 5). یک شناسه زمان واحد برای کشف جریان های فرآیند، اندازه گیری زمان بین تغییرات وضعیت، و زمان اجرای کل فرآیند از ابتدا تا انتها کافی است.
شکل 19: اگر شما دارای شناسه زمان شروع و پایان هستید، مطمئن شوید که هر دو را شامل می شود.
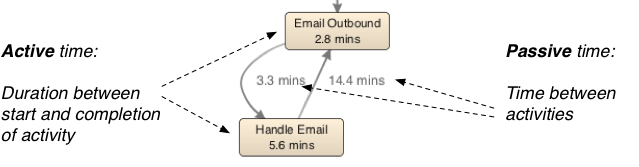
با این حال، گاهی اوقات شما دارای چندین شناسه زمان برای شروع و پایان یک فعالیت هستید. این عالی است زیرا به شما امکان می دهد نه تنها زمان بین مراحل مختلف فرآیند بلکه مدت زمان واقعی اجرای یک فعالیت را نیز اندازه گیری کنید. اگر برای هر فعالیت دو شناسه زمان دارید، می توانید به سادگی هر دو را به عنوان یک ستون شناسه زمان پیکربندی کنید، همانطور که در شکل 19 نشان داده شده است. Disco زودترین شناسه زمان را شروع و آخرین شناسه زمان را تکمیل فعالیت برای هر ردیف تفسیر خواهد کرد.
در نتیجه، زمان فعال (جایی که کسی در واقع روی فعالیت کار می کند) و زمان غیرفعال (جایی که هیچ اتفاقی برای پرونده نمی افتد) می تواند در تجزیه و تحلیل تمایز داده شود. به عنوان مثال، در شکل 20 شما یک قطعه از نقشه فرآیند حاصل را مشاهده می کنید، که در آن میانگین مدت زمان به فعالیت ها و همچنین به زمان های (بیکار) بین آنها متصل شده است. برای کسب اطلاعات بیشتر در مورد چگونگی درج نقشه های فرآیند در Disco با اطلاعات عملکرد، به Performance Metrics مراجعه کنید.
شکل 20: اگر شناسه زمان شروع و پایان در دسترس باشد، سپس زمان اجرای (فعال) و زمان انتظار (غیرفعال) را می توان در تجزیه و تحلیل متمایز کرد.
**در برخی موارد، ممکن است شما حتی بیش از دو شناسه زمان داشته باشید. به عنوان مثال، در شکل 21 قطعه دیگری از ورودی سیستم تلفنی نشان داده شده است. سه ستون وجود دارد که اطلاعات مربوط به شناسه زمان را نگه می دارند: ACT_CREATED، ACT_START، و ACT_END:
در ستون ACT_END همیشه شناسه زمان تکمیل برای فعالیت نماینده را نگه می دارد.
ستون ACT_START زمان شروع واقعی را برای فعالیت های زمان بندی شده نگه می دارد؛ برای فعالیت های بدون زمان، فیلد مربوطه خالی است.
ACT_CREATED همیشه پر است، اما برای فعالیت های زمان بندی شده، زمان شروع منعکس کننده زمان شروع واقعی نیست. تفاوت زمانی بین ACT_START و ACT_CREATED برای فعالیت های زمان بندی شده برای تجزیه و تحلیل مرکز تماس بسیار مهم است زیرا زمان بندی بسیار مهم است.**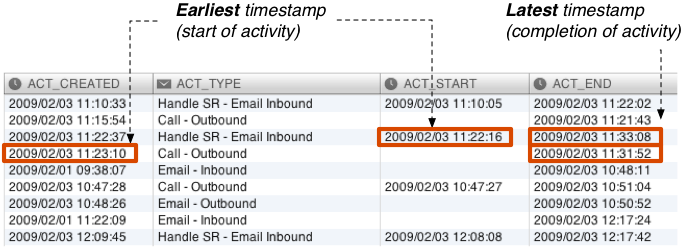
شکل 21: در میان چندین ستون شناسه زمان در هر ردیف، اولین آن به عنوان شروع و آخرین آن به عنوان تکمیل فعالیت گرفته می شود.
با Disco، این وضعیت به راحتی قابل حل است. به سادگی همه سه ستون را در طول پیکربندی به عنوان ستون شناسه زمان وارد کنید و اولین و آخرین شناسه زمان به عنوان زمان شروع و پایان هر فعالیت انتخاب می شوند.
تنظیم مجدد پیکربندی import
همانطور که در Combining Multiple Case ID, Activity, or Resource Columns و Swapping Cases, Activities, and Resources نشان داده شده است، اغلب می توان دیدگاه های مختلفی از فرآیند خود را اتخاذ کرد. برای کاوش در این دیدگاه های مختلف، یا شاید برای اصلاح اشتباه پیکربندی، گاهی اوقات می خواهید پیکربندی مجموعه داده خود را بعد از اینکه واردات را تکمیل کرده اید تغییر دهید.
در Disco، می توانید پیکربندی واردات خود را به دو روش مختلف تغییر دهید:
-
دکمه Reload را در نمای پروژه فشار دهید و به صفحه پیکربندی بازگردانده می شوید همانطور که در شکل 22 و شکل 23 نشان داده شده است.
-
به سادگی همان فایل را دوباره وارد کنید و آن را به روش دیگری پیکربندی کنید. Disco تنظیمات پیکربندی خود را از آخرین بار که آن را وارد کردید به خاطر خواهد سپرد. بنابراین، یک واردات مجدد همان اثر را دارد که با استفاده از دکمه Reload استفاده می شود.
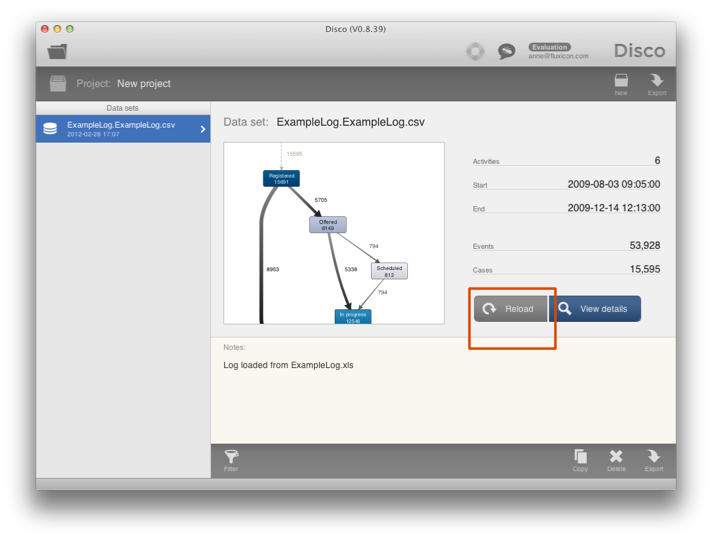 شکل 22: دکمه Reload راهی سریع برای بازگشت به صفحه پیکربندی برای بررسی نحوه نمایش داده ها، احتمال رفع اشتباهات پیکربندی یا گرفتن دیدگاه های جایگزین در مورد فرآیند شما است: فشار دادن Reload در نمای پروژه …
شکل 22: دکمه Reload راهی سریع برای بازگشت به صفحه پیکربندی برای بررسی نحوه نمایش داده ها، احتمال رفع اشتباهات پیکربندی یا گرفتن دیدگاه های جایگزین در مورد فرآیند شما است: فشار دادن Reload در نمای پروژه …
 شکل ۲۳: به شما باز میگرداند تا به صفحه پیکربندی برگردید.
شکل ۲۳: به شما باز میگرداند تا به صفحه پیکربندی برگردید.
در صورتی که قبلاً برخی از کارهای فیلترینگ را (برای مشاهده فیلترینگ) انجام دادهاید که نیاز است آن را حفظ کنید اما همچنان میخواهید پیکربندی را تغییر دهید، دوباره بارگذاری فایل اصلی به شما کمک نخواهد کرد. به جای آن، میتوانید به این ترتیب عمل کنید:
- مجموعه دادههای فعلی فیلترشده را به عنوان یک فایل CSV صادر کنید (برای مشاهده فرآیند صدور مجموعه دادهها).
- فایل CSV صادرشده را وارد کنید و آن را به دلخواه پیکربندی کنید.
وارد کردن مجموعه دادههای پیشپیکربندی شده در اغلب موارد، نقطه شروع دادهها فرمت CSV یا XLS است که قبلاً توضیح داده شد. با این حال، شما همچنین میتوانید مجموعه دادهها را با فرمتهای استاندارد لاگ رویدادی مانند MXML و XES (MXML و XES) وارد کنید. علاوه بر این، میتوانید فایلهای لاگ فشرده شده Disco (فایلهای لاگ Disco) و پروژههای کامل Disco (پروژههای Disco) را نیز وارد کنید.
MXML و XES فرمت Mining XML (MXML) به عنوان یک فرمت استاندارد برای لاگهای رویدادی چندین سال است که وجود دارد. فرمت EXtensible Event Stream (XES) جانشین MXML است و در سال 2010 توسط گروه کار IEEE برای ماینینگ فرآیند تأیید شده است.
استفاده از فرمتهای استاندارد برای تسهیل تعامل بین ابزارهای مختلف کاربرد دارد. به عنوان مثال، لاگها با فرمت MXML یا XES میتوانند توسط ابزارهای ماینینگ فرآیند دیگر مانند مجموعه ابزار دانشگاهی ProM بارگذاری شوند. Disco ارزش زیادی را بر همکاری قرار داده و تمام فرمتهای استاندارد لاگ رویدادی که در حال استفاده هستند را وارد و صادر میکند. بیشتر در مورد انواع استاندارد فرمت لاگ رویدادی پشتیبانی شده میتوانید در مورد صدور مجموعه دادهها بخوانید.
حتی اگر با سایر ابزارهای فرآیندکاوی کار نکنید، وارد کردن MXML یا XES همچنان برای شما مفید است:
۱. بدون نیاز به پیکربندی مجموعههای داده صادرشده در MXML یا XES اطلاعات پیکربندی را از پیش دارند (در مورد شناسههای مورد، فعالیتها، زمانها و غیره). بنابراین، اگر میخواهید یک مجموعه داده را با یک همکاری که همچنین از Disco استفاده میکند، مبادله کنید، میتوانید یک فایل MXML یا XES برای او بفرستید تا او بتواند مرحله پیکربندی را کاملاً از بین ببرد.
به این ترتیب، نیاز به توضیح دادن اینکه کدام ستونها باید چگونه پیکربندی شوند ندارید؛ بلکه او فقط فایل را باز کرده و به صورت مستقیم نقشه فرآیند را مشاهده میکند.
یا به همین ترتیب، اگر میخواهید نسخههای فیلتر یا پیکربندی مختلف لاگ رویدادی خود را به عنوان فایلهایی برای خود نگه دارید، ذخیره آنها با فرمت استاندارد MXML یا XES شما را از مرحله پیکربندی در زمان وارد کردن مجدد این فایلها نجات میدهد.
۲. وارد کردن سریعتر علاوه بر اینکه مرحله پیکربندی در زمان وارد کردن اجتناب میشود، خواندن یک مجموعه داده پیشپیکربندی شده همچنین به دلیل مرتب بودن از قبل (بر خلاف سطرهای یک فایل CSV که هنوز باید توسط Disco مرتب شوند) کارآمدتر است.
برای مجموعههای داده بزرگ، این تفاوت میتواند یک افزایش سرعت ۱۰ برابر (و بیشتر) در زمان وارد کردن به همراه داشته باشد.
اگر فایلهای MXML یا XES داشته باشید که میخواهید به صورت متفاوتی مجدداً پیکربندی کنید، هنوز میتوانید آنها را به صورت یک فایل CSV صادر کرده و مجدداً آن CSV را وارد کنید (برای اطلاعات بیشتر به تنظیمات وارد کردن مراجعه کنید).
فایلهای لاگ Disco بارگذاری مجموعههای داده با فرمت MXML یا XES از وارد کردن دادههای CSV سریعتر است (برای اطلاعات بیشتر به MXML و XES نیز ببینید)، اما هیچ چیز به سرعت بارگذاری دادهها با فرمت Native Disco Log Files (FXL) نمیرسد. FXL یک فرمت مختص (بدون استاندارد) است اما بهترین انتخاب است اگر نیاز به مبادله با مجموعههای داده بسیار بزرگ با یک کاربر دیگر Disco دارید.
به عنوان مثال، برای یکی از لاگهای بنچمارک بزرگ ما، وارد کردن فایل CSV (شامل مرتبسازی) ۳.۵ ساعت طول کشید، وارد کردن فایل MXML حدود ۲۰ دقیقه طول کشید و فایل FXL در حدود یک دقیقه خوانده شد.
فایلهای با فرمت FXL همچنین اندازه فایل کوچکتری نسبت به لاگهای استاندارد فشرده XML و CSV دارند.
“I need to merge multiple files”
در حال حاضر، تنها فایلهای تکی قابل وارد کردن با Disco هستند. اگر قسمتهایی از لاگ رویداد شما در چندین مجموعه داده پخش شده باشد، نیاز دارید قبل از شروع تجزیه و تحلیل ماینینگ فرآیند، کار پیشپردازش اضافی انجام دهید. برای انجام این ترکیب، میتوانید از پایگاهدادهها یا ابزارهای تخصصی تبدیل داده (به عنوان مثال، ابزارهای ETL مانند KNIME) استفاده کنید.
با پشتیبانی IT که دادهها را برای شما استخراج کردهاند تماس بگیرید، یا با ما تماس بگیرید تا به شما کمک کنیم.
“The Start button is greyed out”
همانطور که در شکل ۶ نشان داده شده است، شما تنها میتوانید وارد کردن فایل خود را شروع کنید پس از پیکربندی تمام ستونهای مورد نیاز (شناسه مورد و فعالیت باید تنظیم شوند).
“Disco has problems reading my file”
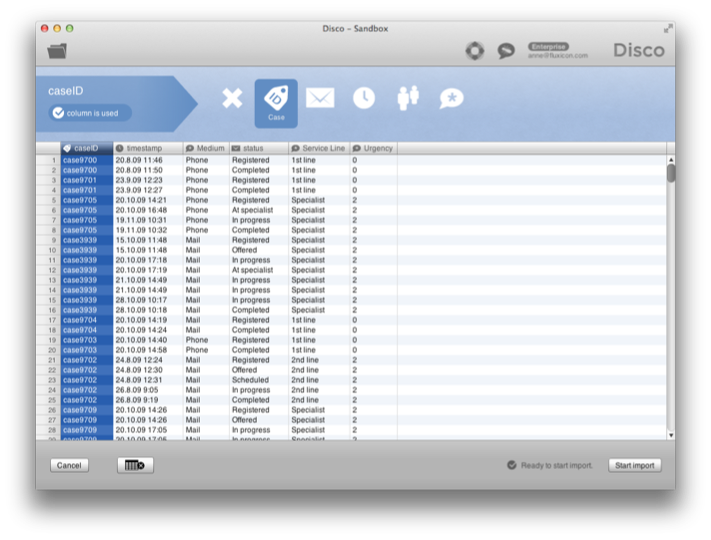
اگر تمام سطرها در فایل CSV یا اکسل شما نتوانند خوانده شوند، Disco به شما اطلاع میدهد (شکل ۲۴ را ببینید).

شکل ۲۴: اگر Disco خطاهایی را در حین وارد کردن گزارش کند، حتماً از فایل مبدأ در شماره خط داده شده برای پیدا کردن مشکل استفاده کنید.
برای فهمیدن مشکل، فایل را باز کنید و خطی که گزارش شده است را با خط قبلی مقایسه کنید. آیا تفاوتی مشاهده میکنید؟ آیا خط مشکلآفرین دارای ستونهای بیشتر یا کمتر از سایر خطوط قبلی است؟ آیا نقل قولهای اشتباه وجود دارد؟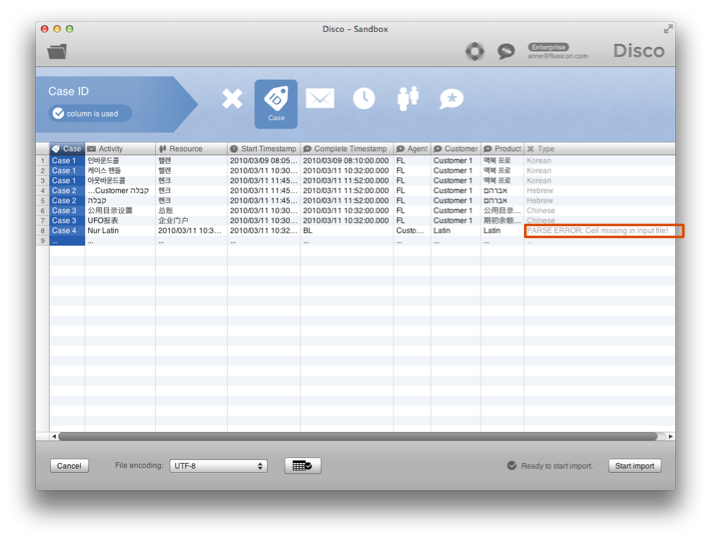 شکل ۲۵: فایل مبدأ که باعث ایجاد پیام خطا در شکل ۲۴ شد: خط ۸ یک ستون کمتر از سایر سطرها دارد. Disco سلول خالی در انتهای سطر را پر میکند اما شما را از عدم تطابق آگاه میکند.
شکل ۲۵: فایل مبدأ که باعث ایجاد پیام خطا در شکل ۲۴ شد: خط ۸ یک ستون کمتر از سایر سطرها دارد. Disco سلول خالی در انتهای سطر را پر میکند اما شما را از عدم تطابق آگاه میکند.
به عنوان مثال، پیام خطا در شکل ۲۴ هنگام تلاش برای خواندن فایلی نمایش داده شد که در شکل ۲۵ نمایش داده شده است. این فایل یک قطعه تغییر یافته از لاگ نمونه است برای تست اسکریپتهای غیر لاتین مانند کرهای، عبری و چینی. وقتی که خط آخر را برای تست نویسههای لاتین اضافه کردم، فراموش کردم برای ستون منبع در فایل مبدأ مقداری وارد کنم. به عنوان نتیجه، میتوانید ببینید که تمام ستونهای دیگر یک واحد به چپ شیفت یافتهاند و خط شماره ۸ یک سلول در انتهای سطر را از دست داده است.
«من نمادهای عجیب میبینم» Disco به طور خودکار رمزگذاری متن مجموعه داده شما را تشخیص میدهد و همچنین میتواند با زبانهایی که نمادهای خاص دارند (مانند “ü” در آلمانی) برخورد کند. اگر متوجه شوید که کاراکترها در مجموعه داده شما به درستی خوانده نمیشوند، اطمینان حاصل کنید که فایل خود را با فرمت یونیکد (UTF-8) ذخیره کردهاید. [2]
اگر Disco به درستی رمزگذاری فایل شما را تشخیص نداده باشد، همچنین میتوانید سایر رمزگذاریها را از لیست موجود در پایین سمت چپ صفحه پیکربندی امتحان کنید (شکل ۲۶ را ببینید). هنگامی که یک رمزگذاری جدید را انتخاب میکنید، Disco فایل CSV شما را با رمزگذاری انتخاب شده مجدداً بارگذاری میکند و شما میتوانید در پیشنمای صفحه پیکربندی ببینید که آیا نویسههای شما اکنون به درستی نمایش داده میشوند یا خیر.
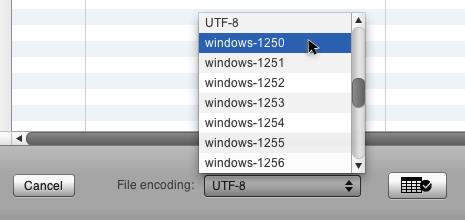
شکل ۲۶: همچنین میتوانید فایل CSV خود را با یک رمزگذاری واضح دوباره بارگذاری کنید، در صورتی که تشخیص خودکار شکست بخورد.
هنگامی که فایل CSV خود را در اکسل باز میکنید، گاهی اوقات همه نمادها به درستی تفسیر نمیشوند. هنگامی که با مشکل مواجه میشوید که نویسههای خاص به درستی نمایش داده نمیشوند، سعی کنید از طریق اکسل عبور نکنید و فایل CSV را مستقیماً به Disco وارد کنید.
Disco پشتیبانی کامل از یونیکد را فراهم میکند، به این معنا که مجموعههای داده از هر زبان (همچنین زبانهای راست به چپ مانند عبری و عربی) قابل خواندن هستند و به درستی نمایش داده میشوند (شکل ۲۷ را ببینید).
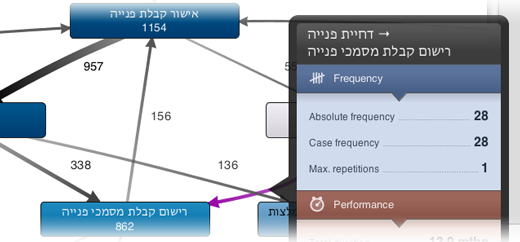
شکل ۲۷: از طریق پشتیبانی از یونیکد در Disco، مجموعههای داده از هر زبان (همچنین زبانهای راست به چپ مانند عبری و عربی) قابل خواندن هستند و به درستی نمایش داده میشوند.


بدون دیدگاه